La matematica dietro la PQC: i codici
Introduzione
Oltre ai reticoli, fondamenta della lattice-based cryptography, un’altra struttura matematica utilizzata per costruire schemi di crittografia post-quantum è rappresentata dai codici a correzione d’errore, più brevemente codici.
I codici nascono nel contesto delle telecomunicazioni per individuare e correggere gli errori che possono verificarsi nella trasmissione di un messaggio attraverso un canale di comunicazione rumoroso; il loro compito è quello di permettere al destinatario di leggere il messaggio così come è stato inviato anche se questo ha subito delle variazioni durante la trasmissione. Al contempo, oggi vedono largo utilizzo nell’ambito della crittografia post-quantum; infatti, su di essi possono essere costruiti problemi computazionali difficili da risolvere anche per un computer quantistico.
I crittosistemi definiti su tali problemi appartengono alla classe detta code-based cryptography. Questa branca della crittografia asimmetrica ha origine alla fine degli anni 70 con lo schema di cifratura a chiave pubblica di Robert McEliece (1978), vedendo in seguito altri risultati di rilevante importanza come il lavoro (versione duale di McEliece) di Harald Niederreiter (1986) e lo schema di firma digitale ideato da Courtois, Finiasz e Sendrier (2001).
La crittografia basata sui codici è quindi coetanea al ben più noto RSA e proprio grazie alla sua longeva età ha dimostrato nel tempo di essere affidabile, arrivando ad essere una delle protagoniste del processo di standardizzazione del NIST.
Codici a correzione d’errore
Supponiamo di voler inviare un messaggio x attraverso un canale di comunicazione. Dobbiamo assumere che il canale sia “rumoroso”, cioè che lungo il canale il messaggio possa subire delle variazioni, dette errori, e quindi che l’informazione ricevuta dal destinatario non sia sempre la medesima che è stata inviata.
Più precisamente, assumiamo che ogni volta che viene mandato un messaggio ci sia una probabilità p che ogni bit del messaggio possa essere modificato.
I codici a correzione di errore vengono introdotti in questo contesto per individuare e correggere tali alterazioni.
L’idea principale della teoria dei codici è quella di aggiungere della ridondanza al messaggio, in modo che, nonostante gli errori introdotti, si sia in grado di ricostruire il messaggio originale che era stato inviato a partire da quello ricevuto.
Un esempio semplice di codice a correzione d’errore è il codice a ripetizione (repetition code) che per ogni bit in input, restituisce in output lo stesso bit ripetuto un certo numero di volte. Per esempio, il messaggio 10110 può essere codificato con il codice a ripetizione con fattore 3 in 111 000 111 111 000.
Quando parliamo di codici è opportuno introdurre due strumenti fondamentali che svolgono la funzione di codifica e decodifica del messaggio: l’encoder (codificatore) e il decoder (decodificatore).
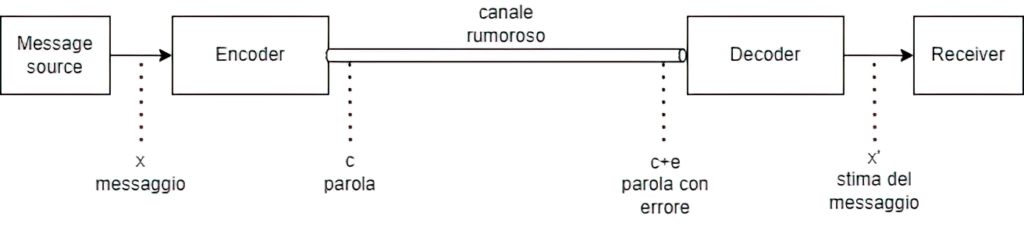
Il messaggio x viene codificato attraverso l‘encoder in una parola (codeword) c. Visto che durante la codifica viene aggiunta ridondanza, la parola sarà più lunga del messaggio. Come abbiamo detto, quando la parola viene inviata attraverso un canale di comunicazione, questa potrebbe subire un errore e. Quando il decoder riceverà y=c+e, avrà il compito di decodificarlo in un messaggio quanto più vicino possibile al messaggio iniziale x, e quindi di individuare e correggere l’errore e.
Vediamo un esempio con il sopracitato codice a ripetizione. Supponiamo che il codice \mathcal{C} codifichi un solo bit con 5 ripetizioni dello stesso bit, allora il bit 0 diventa 00000 mentre il bit 1 diventa 11111. Supponiamo che il decoder a destinazione riceva il messaggio 00010: visto che i messaggi in arrivo possibili sono soltanto due e sono la codifica di 0 e la codifica di 1, il destinatario individua la presenza dell’errore (error detection) e può essere confidente che il mittente volesse inviargli il bit 0 codificato come 00000 e quindi correggerlo (error correction).
Codici lineari
Nell’esempio precedente, l’insieme delle parole del codice è
\mathcal{C}=\{00000, 11111\} che può essere descritto in termini matematici come
\mathcal{C}=\{xG \mid x\in \{0,1\}\} dove G è la matrice 1\times 5 G=(1, 1, 1, 1, 1).
Quando possiamo descrivere un codice attraverso una matrice, diciamo che il codice è lineare. I codici lineari sono una classe fondamentale della teoria dei codici a correzione d’errore e sono di particolare rilievo per diverse applicazioni, tra cui la crittografia.
Intuitivamente, un codice lineare può essere visto come la versione discreta di un reticolo. Supponiamo di avere uno spazio e consideriamo un sottoinsieme di punti in esso. Un reticolo è un determinato sottoinsieme di punti su uno spazio continuo, intuitivamente non ci sono buchi tra i punti dello spazio, mentre un codice è un determinato sottoinsieme di punti su uno spazio discreto. Questo vuol dire che mentre sui reticoli possiamo avvicinarci a piacere ad un punto del reticolo muovendoci nello spazio continuo, nei codici abbiamo una quantizzazione delle distanze.
Più formalmente, un codice lineare è definito da tre parametri, q,n,k nella notazione [n,k]_q. Il primo parametro q è una potenza di un numero primo e rappresenta la dimensione dell’alfabeto delle parole del codice . Denotiamo con \mathbb{F}_q il campo finito con q elementi, e con \mathbb{F}_q^n lo spazio vettoriale di dimensione n su \mathbb{F}_q, ovvero le n-uple con elementi in \mathbb{F}_q. Un codice lineare su \mathbb{F}_q di dimensione k e lunghezza n è un sottospazio k-dimensionale di \mathbb{F}_q^n.
Se q=2, abbiamo che \mathbb{F}_2 = \{0,1\} e si dice che il codice lineare è binario.
Solitamente un codice lineare viene rappresentato attraverso la sua matrice generatrice. Una matrice generatrice G per il codice \mathcal{C} [n,k]_q è una matrice k \times n le cui righe formano la base di \mathcal{C}, cioè \mathcal{C}=\{xG \mid x \in \mathbb{F}_q^k\}.
Decoding Problem
Il problema matematico costruito sui codici di interesse per la crittografia è il decoding problem, ovvero il problema di trovare la parola del codice più vicina[1] ad un dato vettore appartenente allo spazio su cui il codice è definito. In altre parole, dato un vettore y=c+e \in \mathbb{F}_q^n, si vuole capire quale parola c è stata inviata (e quindi quale messaggio x).
Un ingrediente fondamentale per lo studio di questo problema è il peso di Hamming (Hamming weight) \mathrm{w}, definito come la funzione che va da \mathbb{F}_q^n nei numeri naturali \mathbb{N}, che associa ad ogni vettore il numero delle sue entrate non nulle. A partire da questo, è possibile costruire una distanza su \mathbb{F}_q^n detta distanza di Hamming, data dalla seguente mappa
\mathrm{d_H}(a,b)=\mathrm{w}(a-b).
Un possibile approccio al decoding problem, conosciuto come minimum distance decoding, consiste nel decodificare y con la parola di distanza di Hamming minima da y. Formalmente, dato y\in \mathbb{F}_q^n, consideriamo la parola c_y\in\mathcal{C} tale che \mathrm{d_H}(y,c_y)=\min\{\mathrm{d_H}( y,c) \mid c\in \mathcal{C}\}.
In generale, possiamo definire la distanza minima (minimum distance) di un codice lineare \mathcal{C} come il minimo tra i pesi di tutte le parole non nulle, cioè
\mathrm{d}=\min\{w(x)\mid x\neq0\}=\min\{\mathrm{d_H} (x,y) \mid x,y\in \mathcal{C}, x \neq y\}.
Diciamo che \mathcal{C} è un codice [n,k,d]_q se è un codice lineare su \mathbb{F}_q di dimensione k, lunghezza n e distanza minima d; mentre, nel caso in cui la distanza minima non sia nota, scriviamo [n,k]_q.
La distanza di un codice dà indicazioni sulla sua capacità di correzione dell’errore. Infatti, supponiamo di avere un [n,k,d]_q codice, allora la sua capacità di correzione è data da t=\lfloor\frac{d-1}{2}\rfloor. Questo vuol dire che se codifichiamo un messaggio x in una parola c del codice e mandiamo c sul canale rumoroso, se l’errore e introdotto sul canale ha al più t entrate diverse da zero (ovvero peso di Hamming al più t), allora esiste un algoritmo di decodifica \mathcal{D} che preso in input y=c+e, restituisce c.
Sebbene in letteratura siano note diverse famiglie di codici lineari che ammettono una decodifica efficiente, in generale dato un codice \mathcal{C} non è detto che un tale algoritmo sia noto; infatti, il decoding problem su un codice random appartiene ad una classe di problemi estremamente difficili noti come problemi NP-completi[2].
Il fatto che codificare un messaggio sia facile, mentre decodificarlo sia un problema difficile, costituisce il concetto di trapdoor sul quale si basa la sicurezza della crittografia basata su codici. Infatti, i problemi sui codici utilizzati in crittografia per costruire algoritmi post-quantum sono tutti varianti del decoding problem.
I codici nella PQC
La crittografia basata sui codici ha tra i suoi pregi la longevità, essendo presente in letteratura da ormai più di 40 anni. Il primo schema basato sui codici è stato proposto da McEliece nel 1978, due anni dopo la formalizzazione del Diffie-Hellman e un anno dopo RSA. Mentre, ad esempio, gli schemi sui reticoli sono più recenti: il primo sistema sui reticoli, NTRU, è stato pubblicato nel 1996 e il problema del LWE utilizzato in CRYSTAL-Kyber e CRYSTAL-Dilithium nel 2005.
Questo ha fatto sì che i problemi su cui si basano gli schemi code-based siano stati studiati a fondo dalla comunità crittografica, rafforzando la fiducia che oggi possano costituire la base adatta su cui sviluppare schemi crittografici resistenti ad attacchi di un computer quantistico.
Nonostante ciò, il principale svantaggio che negli anni si è riuscito solo in parte a limare, è quello dell’efficienza. Infatti, per quanto riguarda la dimensione delle chiavi e/o dei cifrati, si ha almeno un ordine di grandezza di differenza rispetto, ad esempio, ai sistemi basati sui reticoli. Questa maggiore dimensione delle chiavi rende ad oggi difficoltoso l’utilizzo di code based cryptography in alcuni contesti caratterizzati da stringenti requisiti di performance o memoria.
Al primo round della competizione del NIST, la categoria code-based vantava 19 schemi di key encapsulation mechanism (KEM) e 3 di firma digitale. Attualmente, nel quarto round, dopo la decisione del NIST di standardizzare il KEM basato sui reticoli CRYSTAL-Kyber, tutti i candidati nella categoria KEM sono basati su codici. Nessuno schema di firma, invece, ha superato il primo round, ma 6 nuovi schemi sono stati recentemente proposti nella competizione del NIST parallela focalizzata sulla selezione di firme digitali post-quantum[3].
Nel corso dei prossimi articoli di questa rubrica verranno approfonditi i tre KEM basati su codici (Classic McEliece, BIKE e HQC) ancora in corso di valutazione nel quarto round.
[1] Secondo un’opportuna metrica.
[2] Berlekamp, E., McEliece, R., and Van Tilborg, H. On the inherent intractability of certain coding problems (corresp.). IEEE Transactions on Information Theory 24, 3 (1978), 384–386.
[3] Tra gli schemi proposti ce ne sono altri due che basano la loro sicurezza su assunzioni costruite sui codici ma appartengono alla categoria del recente paradigma “MPC-in-the-head”.
Questo articolo appartiene ad una serie di contributi, a cura del Gruppo di Ricerca in Crittografia di Telsy, dedicata al calcolo quantistico e alle sue implicazioni sulla Crittografia. Per la consultazione di altri articoli si rimanda all’indice della rubrica.
Per altri articoli relativi ai temi Quantum e Crittografia si rimanda alle relative categorie nel blog.
Gli autori
Veronica Cristiano, laureata triennale in Matematica presso l’Università di Pisa e laureata magistrale in Matematica con specializzazione in Crittografia presso l’Università di Trento, entrata a far parte del gruppo di ricerca in Crittografia di Telsy a metà del 2021.
Giuseppe D’Alconzo, laureato in Matematica con specializzazione in Crittografia presso l’Università di Trento, ha svolto nel 2019 uno stage presso Telsy, occupandosi di Multi-party Computation e Attribute Based Encryption. Attualmente è studente di dottorato in Matematica Pura e Applicata presso il Politecnico di Torino, con una borsa a tema “Crittografia Post-Quantum” nell’ambito del programma UniversiTIM e in collaborazione con il Gruppo di Ricerca di Telsy.